
Building Conversational SQL Agents with LangChain

Debakshi B.

Sep 10, 2025
{kind=link}
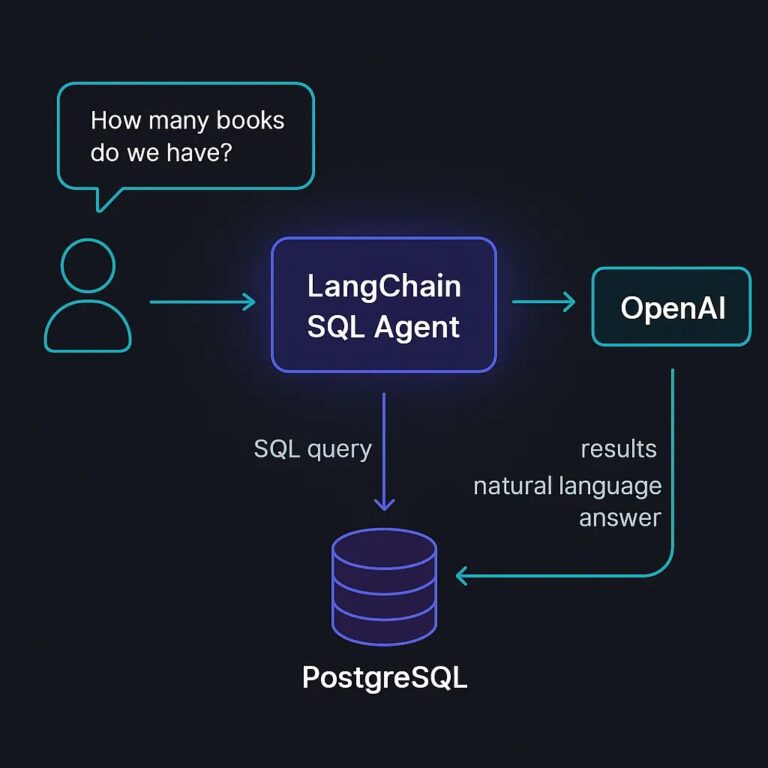
Ever wanted to build a chatbot that can answer specialized questions directly from your database? We had this exact requirement in one of our projects.
Initially, we used standard LangChain with custom tool calling — creating separate functions for each database table and manually crafting SQL queries. The result? High latency, an unmaintainable codebase that grew exponentially with our database, and memory management nightmares.
The Problems We Faced:
- Codebase exploded as new tables were added
- Manual SQL generation slowed everything down and introduced errors
- Supporting new queries required heavy dev effort
- Adding new features on top of the chatbot became difficult
- Implementing context management (bot memory) was tedious and error-prone
Then we discovered LangChain’s SQL agent, and how PostgreSQL and LangChain can take care of most of our needs readily. In this tutorial, we’ll show you how to build the solution that reduced our codebase complexity by 70% while dramatically improving performance.
What We’ll Build
A complete conversational SQL agent using LangChain, OpenAI, and FastAPI that can handle queries from a book database, like:
- “Show me all books by Stephen King”
- “Which authors have written more than 3 books?”
- “What’s the average rating of science fiction books?”
Prerequisites
- Python 3.9+
- PostgreSQL database
- OpenAI API key
- Basic knowledge of SQL and Python
Setup
pip install fastapi uvicorn langchain-openai langchain-community sqlalchemy psycopg2-binary langchain-postgres
- Authors: stores basic author information like name, year of birth, and nationality.
- Books: stores book details such as title, genre, publication year, and rating, with a foreign key linking back to the author.
books_with_authors. This view joins both tables into one unified dataset so that queries can be simplified. Instead of writing complex SQL joins every time, the agent can query the view directly to get books along with their authors.Step 1: Basic SQL Agent
- Natural Language to SQL — The agent takes a plain English question like “List all books with their authors and ratings”.
-
SQL Generation — It automatically generates the appropriate SQL query (for example, selecting from the
books_with_authorsview). - Execution — The query is run against the PostgreSQL database.
- Readable Output — The agent then returns the result in a human-friendly format.
rating is a decimal between 0–5, or that author_id references the authors table.books_with_authors) should be treated as first-class citizens. This allows it to prefer querying the view instead of re-creating the join logic each time, which makes the queries cleaner and more reliable.Console Output:
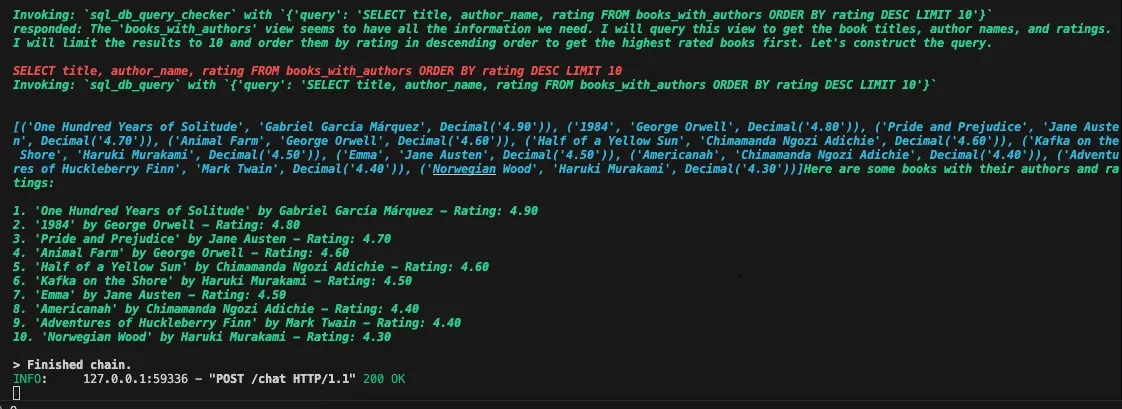
Step 2: Adding Callbacks for Raw Results
SQLResultHandler specifically captures the output from SQL database queries, giving us access to both the agent’s natural language response and the raw data.Step 3: Adding Conversation Memory
PostgresChatMessageHistory requires the session_id to be a UUID string.- Remember previous questions and answers
- Handle follow-up questions naturally
- Maintain context across multiple interactions
- Scale to multiple users/sessions with session IDs
Step 4: FastAPI Web Service
Running the Application
main.py and run:uvicorn main:app --reload
http://localhost:8000. You can test it with:Note: The user_id field must always be a valid UUID, otherwise LangChain will throw us an error.
Testing Your Agent
- “Show me all books published after 2020”
- “Which author has the highest average book rating?”
- “List science fiction books with ratings above 4.0”
- “Who wrote ‘The Shining’?” (followed by “What other books did they write?”)
Complete Working Example
Here’s the full code putting it all together:
Example Request:
{
"message": "List all books with their authors and ratings",
"user_id": "44b11b50-9417-4fa5-8e5d-ea968c6dc7d1"
}
Agent Reply:
{
"reply": "Here are some books with their authors and ratings:\n\n1. 'One Hundred Years of Solitude' by Gabriel García Márquez - Rating: 4.90\n2. '1984' by George Orwell - Rating: 4.80\n3. 'Pride and Prejudice' by Jane Austen - Rating: 4.70\n4. 'Animal Farm' by George Orwell - Rating: 4.60\n5. 'Half of a Yellow Sun' by Chimamanda Ngozi Adichie - Rating: 4.60\n6. 'Kafka on the Shore' by Haruki Murakami - Rating: 4.50\n7. 'Emma' by Jane Austen - Rating: 4.50\n8. 'Americanah' by Chimamanda Ngozi Adichie - Rating: 4.40\n9. 'Adventures of Huckleberry Finn' by Mark Twain - Rating: 4.40\n10. 'Norwegian Wood' by Haruki Murakami - Rating: 4.30",
"raw_sql_result": "[('One Hundred Years of Solitude', 'Gabriel García Márquez', Decimal('4.90')), ('1984', 'George Orwell', Decimal('4.80')), ('Pride and Prejudice', 'Jane Austen', Decimal('4.70')), ('Animal Farm', 'George Orwell', Decimal('4.60')), ('Half of a Yellow Sun', 'Chimamanda Ngozi Adichie', Decimal('4.60')), ('Kafka on the Shore', 'Haruki Murakami', Decimal('4.50')), ('Emma', 'Jane Austen', Decimal('4.50')), ('Americanah', 'Chimamanda Ngozi Adichie', Decimal('4.40')), ('Adventures of Huckleberry Finn', 'Mark Twain', Decimal('4.40')), ('Norwegian Wood', 'Haruki Murakami', Decimal('4.30'))]"
}
Key Benefits
This approach gives you:
- Natural Language Interface: Users can ask questions in plain English
- Conversation Memory: Maintains context across multiple questions
- Raw Data Access: Callbacks provide access to underlying SQL results, or literally anything else you want to do after agent call.
- REST API: Easy integration with web apps, mobile apps, or other services
- Scalable: Supports multiple concurrent users with session management
Working Example from GitHub
The complete working example is available in the GitHub repository: 👉 LangChain SQL Agent Demo (GitHub)
To run it locally:
git clone https://github.com/Silversky-Technology/langchain-sql-agent-guide.git
cd langchain-sql-agent-guide
python -m venv venv
source venv/bin/activate
pip install fastapi uvicorn langchain-openai langchain-community sqlalchemy psycopg2-binary langchain-postgres asyncio
uvicorn main:app --reload
http://localhost:8000!Conclusion
You now have a complete conversational SQL agent that can handle complex database queries through natural language. The modular design makes it easy to extend with additional features like:
- Rate limiting and authentication
- Query result caching
- Support for multiple databases
- Custom response formatting
The combination of LangChain’s SQL agent capabilities with FastAPI’s modern web framework creates a powerful foundation for building intelligent database interfaces.
Full working example is available here: LangChain SQL Agent Demo (GitHub)